ВПЕРЁД ⇒
⇐ НАЗАД
Сортировка вставками (insertion sort)
Объяснение работы алгоритма
Имеется массив, который необходимо отсортировать. Проход по массиву осуществляется слева направо таким образом, что в качестве инварианта выступает отсортированный префикс (левая часть массива).
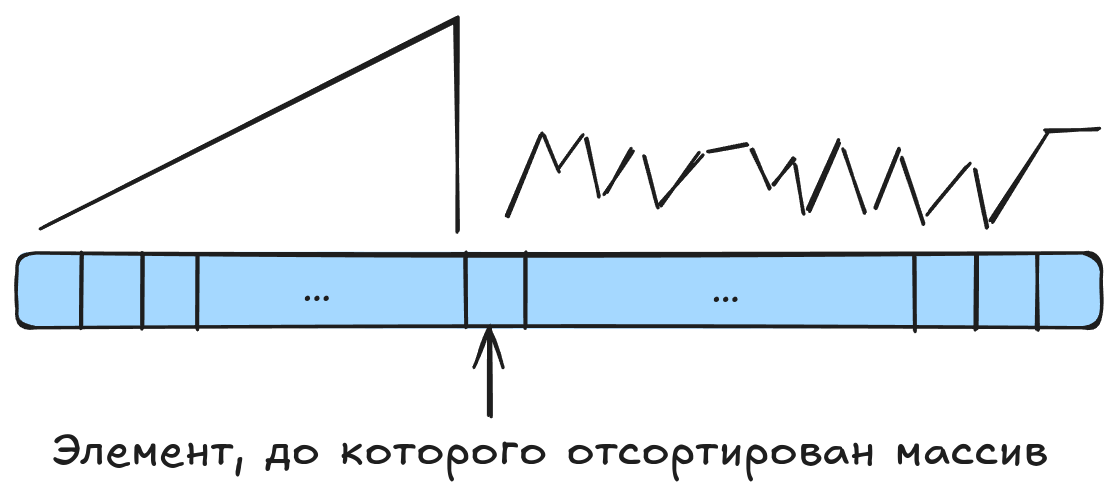
Суть сортировки заключается в следующем:
- Имеется отсортированный префикс (изначальный размер которого равен 0).
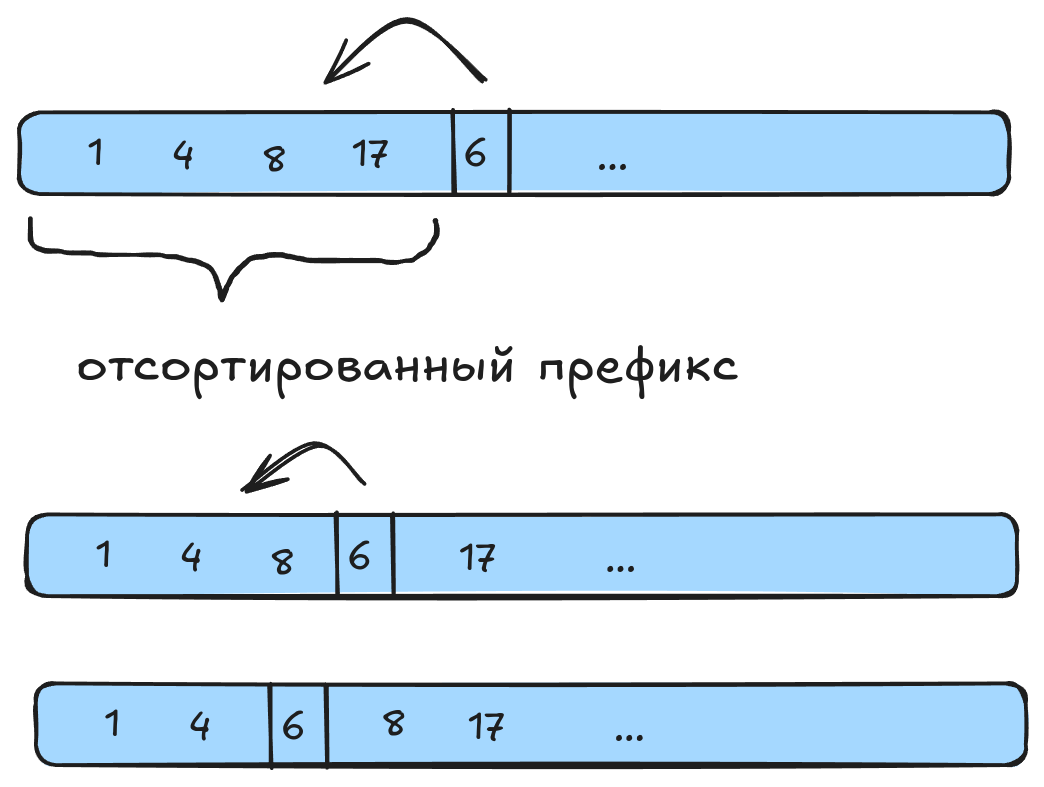
- В качестве нового элемента для добавления в уже отсортированный префикс выбирается первый элемент из правой (ещё не отсортированной) части.
- Новый элемент сдвигается влево до тех пор, пока не начнёт выполняться инвариант.
- Повторяем пункты 1 - 3 до тех пор, пока не будет отсортирован весь массив.
for i = 0..n-1 // Последовательно слева направо начинаем перебор элементов
// из правой неотсортированной части
j=i // Указатель текущей позиции для элемента, который хотим
// сдвинуть влево (вставить в отсортированный префикс).
// Изначально длина отсортированного префикса равна 0.
// При сдвиге влево j будет изменяться и указывать
// на обновлённую позицию элемента.
while j > 0 and a[j] < a[j-1]: // Если значение вставляемого элемента
swap(a[j], a[j-1]) // меньше значения соседнего левого элемента
j = j - 1 // (из отсортированного префикса), то меняем
// местами вставляемый элемент с его
// соседом. Повторяем сдвиг влево
// до тех пор, пока не начнёт
// выполняться инвариант: a[k] >= a[k-1] для
// k = 1..i
Сортировка вставками на английском языке носит название insertion sort.
Оценка времени работы алгоритма
Максимальное время работы алгоритма определяется худшим случаем выбора входных данных. В лучшем случае входные данные уже будут отсортированы в требуемом порядке. В худшем случае входные данные будут изначально отсортированы в обратном (инверсном) порядке.
Лучший случай. Оценка времени работы снизу
Все элементы массива перед запуском работы алгоритма уже расположены в требуемом порядке возрастания/убывания. Алгоритм, фактически, только пройдётся слева направо по всем элементам массива и убедится, что ни один из этих элементов не нуждается в перестановке с другими элементами.
for i = 0..n-1 // количество проверок условия for-цикла равно n+1
// (сначала выполняется n проходов по телу for-цикла
// с выполнением операций проверки и инкрементации переменной i
// в условии цикла, затем выполняется последняя проверка условия
// цикла, показывающая, что проходы по телу цикла больше
// не нужны, поэтому дальнейших инкрементаций переменной i
// больше не будет)
j=i // количество присваиваний в одной итерации for-цикла равно 1
while j > 0 and a[j] < a[j-1]: // количество итераций (проходов
// по телу) while-цикла в каждой
// итерации for-цикла равно 0,
// выполняется только однократная
// проверка условия while-цикла,
// сразу же приводящая к завершению
// while-цикла, само тело цикла
// ни разу не выполняется
swap(a[j], a[j-1]) // перестановки местами отсутствуют
j = j - 1 // декрементация j не выполняется
Наша задача - оценить время работы программы через оценку количества инструкций/команд, выполняемых процессором в процессе работы программы. Для быстрого получения оценки времени работы алгоритма не требуется производить доскональный подсчёт количества инструкций, выполняемых каждой строкой кода. Достаточно присвоить каждой строке кода некоторую символьную константу (отображающую абстрактное число инструкций, содержащихся в одном проходе по строке), помноженную на число проходов по этой строке.
for i = 0..n-1 // k1*(n+1) инструкций за все время работы алгоритма, где
// k1 - количество инструкций, содержащихся в
// строке кода "for i = 0..n-1".
// На самом деле, количество инструкций будет чуть меньше:
// k1*n + m, где m < k1 (поскольку в последней проверке условия
// цикла последующую инкрементацию переменной i выполнять
// больше не потребуется). Но, для упрощения подсчёта, можно
// выполнить округление числа инструкций в большую сторону:
// k1*n + k1 = k1*(n+1)
j=i // k2*n инструкций за все время работы алгоритма, где
// k2 - количество инструкций, содержащихся
// в строке кода "j=i"
while j > 0 and a[j] < a[j-1]: // k3*n инструкций за все время
// работы алгоритма, где
// k3 - количество инструкций,
// содержащихся в строке кода
// "while j > 0 and a[j] < a[j-1]"
swap(a[j], a[j-1]) // 0 инструкций за все время работы
// алгоритма
j = j - 1 // 0 инструкций за все время работы
// алгоритма
Оценка сложности работы алгоритма снизу определяется следующим образом:
Характеристика означает, что у времени работы алгоритма для лучшего случая имеется нижнее ограничение в виде линейной зависимости (трактовать как “работает не лучше, чем линейная зависимость”). Иначе говоря, характер зависимости не может представлять собой константу, то есть с ростом размера входного массива время работы алгоритма не может оставаться неизменным, а будет линейно увеличиваться.
Таким образом, в лучшем случае время работы алгоритма сортировки вставками линейно зависит от размера входных данных.
Худший случай. Оценка времени работы сверху
Худшая ситуация для алгоритма сортировки - когда элементы исходного массива расположены в противоположном порядке от требуемого. Например, необходимо отсортировать элементы в порядке возрастания, а в исходном массиве эти элементы расположены в порядке убывания. Тогда придётся поочерёдно передвигать все элементы массива.
for i = 0..n-1 // количество проверок условия for-цикла равно n+1
j=i // количество присваиваний в одной итерации for-цикла равно 1
while j > 0 and a[j] < a[j-1]: // количество итераций while-цикла в одной
// итерации for-цикла никогда не превышает
// значение n, то есть линейно увеличивается
// с ростом величины n.
// На самом деле, максимально возможное
// количество последовательных смещений
// элемента влево в массиве из n элементов
// равно n-1. Но, для упрощения процесса
// оценивания, мы можем выбрать число n в
// качестве максимального значения
swap(a[j], a[j-1]) // количество перестановок в одной итерации
// while-цикла равно 1
j = j - 1 // количество присваиваний в одной итерации
// while-цикла равно 1
Используя подход с константами (каждая из которых отображает абстрактное число инструкций, содержащихся в одном проходе по строке кода), получаем:
for i = 0..n-1 // k1*(n+1)
j=i // k2*n
while j > 0 and a[j] < a[j-1]: // (k3*n) * n
swap(a[j], a[j-1]) // (k4*n) * n
j = j - 1 // (k5*n) * n
Тогда оценка сложности работы алгоритма сверху определяется следующим образом:
Характеристика означает, что у времени работы алгоритма для худшего случая имеется верхнее ограничение в виде квадратичной зависимости (трактовать как “работает не хуже, чем квадратичная зависимость”).
Таким образом, в худшем случае время работы алгоритма сортировки вставками квадратично зависит от размера входных данных.
Упрощение процесса оценивания времени работы алгоритма через подбор подходящих значений весовых коэффициентов k
Для алгоритма сортировки вставками получили, что в лучшем случае сложность алгоритма растёт линейным образом, а в худшем - квадратичным образом:
При оценивании времени работы алгоритма нас интересует только порядок роста сложности вычислений (то есть характер роста), а не точное значение зависимости и коэффициентов . Это означает, что мы имеем право выполнить упрощение полученных оценок таким образом, чтобы при этом они всё ещё продолжали сохранять свой порядок роста, и извлекать информацию о порядке роста сложности вычислений из упрощённых оценок, а не из исходных оценок. Такой подход позволяет упростить и ускорить процесс оценивания сложности вычислений алгоритма.
Упрощение процесса оценивания для наилучшего случая работы алгоритма сортировки вставками
Рассмотрим сначала наилучший случай работы алгоритма:
for i = 0..n-1 // k1*(n+1)
j=i // k2*n
while j > 0 and a[j] < a[j-1]: // k3*n
swap(a[j], a[j-1]) // 0
j = j - 1 // 0
Строки кода (внутри for-цикла) с коэффициентами и обладают константными временами выполнения для любой из итераций цикла, а также выполняются раз каждая за всё время работы программы. Строка кода с коэффициентом , непосредственно задающая for-цикл, выполняется раз. Если мы сделаем предположение, что , , и , то получим упрощенную оценку для , чей порядок роста не изменится в сравнении с исходной оценкой:
Также необходимо отметить, что младший член исходной оценки , не зависящий от и называемый свободным членом полинома, а также равный , появляется по причине того, что в алгоритме число проверок условия for-цикла равно не , а . Из-за этого число инструкций, затрачиваемых на выполнение всех проверок условия for-цикла, оценивается не как , а как . Если в оценке свободный член занулить, то порядок роста обновлённой оценки останется прежним (обратите внимание: зануляется только , соответствующий свободному члену, а не все вхождения в оценку):
Иначе говоря, оценку сложности вычислений для алгоритма сортировки вставками можно было бы получить следующим образом:
for i = 0..n-1 // k1*n = 1*n = n
j=i // k2*n = 0*n = 0
while j > 0 and a[j] < a[j-1]: // k3*n = 0*n = 0
swap(a[j], a[j-1]) // 0
j = j - 1 // 0
Таким образом, можем сделать вывод, что если сложность вычисления строки кода (находящейся внутри тела цикла) является постоянной величиной (то есть сложность: не изменяется от итерации к итерации цикла; не зависит от размера входных данных ) и равна некоторой константе , то при подсчёте сложности вычислений алгоритма такую строку в теле цикла можно игнорировать. Оценку сложности вычислений для всех проходов по заголовку цикла “for i = 0..n-1”, представляющего собой управляющую конструкцию задания количества итераций, зависящего от , игнорировать нельзя и можно полагать равной . Если же количество итераций цикла константно (не зависит от ), то сложность вычислений заголовка цикла можно игнорировать:
for i = 0..n-1 // считаем, что все проходы по
// заголовку for-цикла выполняются за
// время n
j=i // игнорируем строку, так как
// она внутри итерации цикла
// выполняется за константное время
while j > 0 and a[j] < a[j-1]: // игнорируем заголовок, так как
// количество итераций while-цикла в
// пределах одной итерации for-цикла
// не зависит от n (для наилучшего
// случая выполняется только
// однократная проверка условия
// while-цикла, состоящая из k3
// инструкций и приводящая к
// завершению while-цикла после первой
// же проверки, само тело цикла ни
// разу не выполняется)
swap(a[j], a[j-1]) // игнорируем строку, так как
// она выполняется за константное время
// (если быть более точным, то строка
// вообще ни разу не выполняется в
// наилучшем случае работы алгоритма)
j = j - 1 // игнорируем строку, так как
// она выполняется за константное время
// (если быть более точным, то строка
// вообще ни разу не выполняется в
// наилучшем случае работы алгоритма)
Таким образом, основной вклад в сложность вычислений алгоритма будут вносить проходы по for-циклу, количество итераций которого зависит от размера входных данных .
Упрощение процесса оценивания для наихудшего случая работы алгоритма сортировки вставками
Аналогичным образом можно поступить и при оценивании сложности вычислений алгоритма сортировки вставками для наихудшего случая входных данных:
for i = 0..n-1 // k1*(n+1)
j=i // k2*n
while j > 0 and a[j] < a[j-1]: // (k3*n) * n
swap(a[j], a[j-1]) // (k4*n) * n
j = j - 1 // (k5*n) * n
Для , , , и получаем:
for i = 0..n-1 // k1*n = 1*n = n
j=i // k2*n = 0*n = 0
while j > 0 and a[j] < a[j-1]: // (k3*n) * n = (1*n)*n = n*n
swap(a[j], a[j-1]) // (k4*n) * n = (0*n)*n = 0
j = j - 1 // (k5*n) * n = (0*n)*n = 0
Расшифруем, что всё это значит:
for i = 0..n-1 // n (оценка количества проходов)
j=i // 0 (константное время выполнения
// строки внутри итерации for-цикла)
while j > 0 and a[j] < a[j-1]: // n * n (значение n проходов по циклу
// while, помноженное на значение n
// проходов по циклу for).
// В данном случае игнорировать оценку
// сложности вычислений для заголовка
// while-цикла нельзя, так как эта
// сложность изменяется от итерации
// к итерации for-цикла (зависит от
// размера входных данных n)
swap(a[j], a[j-1]) // 0 (константное время выполнения
// строки внутри итерации while-цикла)
j = j - 1 // 0 (константное время выполнения
// строки внутри итерации while-цикла)
Упрощение процесса оценивания времени работы алгоритма через замену сложных подвыражений их асимптотическими обозначениями
Что мы уже знаем:
Упрощение процесса оценивания для наилучшего случая работы алгоритма сортировки вставками
Рассмотрим сначала наилучший случай работы алгоритма:
for i = 0..n-1 // k1*(n+1)
j=i // k2*n
while j > 0 and a[j] < a[j-1]: // k3*n
swap(a[j], a[j-1]) // 0
j = j - 1 // 0
Перепишем оценки сложностей выполнения строк кода в алгоритме через использование их асимптотических обозначений:
for i = 0..n-1 // O(n)
j=i // O(n)
while j > 0 and a[j] < a[j-1]: // O(n)
swap(a[j], a[j-1]) // 0
j = j - 1 // 0
Поскольку алгоритм оценивался для наилучшего случая входных данных, то полученная оценка представляет собой ограничение сложности алгоритма снизу:
Упрощение процесса оценивания для наихудшего случая работы алгоритма сортировки вставками
Теперь рассмотрим наихудший случай работы алгоритма:
for i = 0..n-1 // k1*(n+1)
j=i // k2*n
while j > 0 and a[j] < a[j-1]: // (k3*n) * n
swap(a[j], a[j-1]) // (k4*n) * n
j = j - 1 // (k5*n) * n
Перепишем оценки сложностей выполнения строк кода в алгоритме через использование их асимптотических обозначений:
for i = 0..n-1 // O(n)
j=i // O(n)
while j > 0 and a[j] < a[j-1]: // O(n^2)
swap(a[j], a[j-1]) // O(n^2)
j = j - 1 // O(n^2)
Корректность работы алгоритма сортировки вставками
Доказательство корректности работы алгоритма:
Инициализация. Перед стартом программы сортировки размер отсортированного префикса равен 0. Это значит, что в префиксе не могут содержаться никакие элементы, чей порядок расположения хоть как-то нарушал бы инвариант цикла, заключающийся в том, что все элементы префикса должны быть расположены в требуемом порядке возрастания/убывания.Сохранение. В качестве нового элемента для добавления в уже отсортированный префикс выбирается первый элемент из правой (ещё не отсортированной) части. Новый элемент сдвигается влево до тех пор, пока не начнёт выполняться инвариант, то есть пока элементы обновлённого префикса не окажутся отсортированными в требуемом порядке возрастания/убывания.Завершение. Поскольку циклическое извлечение элементов из неотсортированной части массива и их помещение в отсортированную часть не приводят к изменению размера всего массива, то рано или поздно таким способом будут перебраны все элементы массива, и при достижении последней позиции массива будет выполнен останов работы алгоритма. Из этого можно заключить, что условие завершения цикла достижимо. По итогам прохода по всем итерациям цикла все элементы из правой неотсортированной части будут поэлементно добавлены в префикс в правильные места (после любой из вставок в префикс нового элемента будет сохраняться инвариант цикла сортировки). В конце работы программы в префиксе окажутся (в отсортированном порядке) все элементы из правой части.
ВПЕРЁД ⇒
⇐ НАЗАД
Источники
- Павел Маврин “АиСД, Семестр 1, Лекция 1. Оценка времени. Сортировка слиянием”
- Инвариант (Wiki)
- Томас Кормен “Алгоритмы. Построение и анализ”. Глава 2 “Приступаем к изучению”, параграф 2.1 “Сортировка вставкой” (стр. 38-45).
Категория
Теги
- Алгоритм Алгоритм
- Инвариант Инвариант
- Инвариант-цикла Инвариант-цикла
- Цикл Цикл
- Сортировка Сортировка
- Сортировка-вставками Сортировка-вставками
- Время-работы Время-работы
- Сложность-по-времени Сложность-по-времени
- Временная-сложность Временная-сложность
- Time-complexity Time-complexity
- Сложность-вычислений Сложность-вычислений
- Big-O Big-O