ВПЕРЁД ⇒
⇐ НАЗАД
Сложность рекурсивных программ
Рекурсивная программа - программа, которая содержит в себе вызов этой же самой программы, но с новыми входными данными (если входные данные будут оставаться неизменными, то рекурсивная программа рискует оказаться в бесконечном цикле выполнения одного и того же вызова, никак не отличающегося от предыдущих и последующих вызовов). Очевидно, что рекурсивные вызовы должны быть конечными (рано или поздно программой должен быть достигнут последний рекурсивный вызов), в противном случае программа будет работать бесконечно, что не имеет никакого смысла, так как любая программа должна в конечном итоге завершить своё исполнение и предоставить пользователю (или другой программе) полезные результаты своей работы. С практической точки зрения исполнение бесконечно рекурсивной программы рано или поздно будет приводить к переполнению стэка вызовов в потоке/процессе операционной системы, то есть программа будет сваливаться с ошибкой.
Сложность рекурсивных программ, использующих инкрементный/декрементный подход изменения входных данных
Рекурсивная программа с инкрементным/декрементным подходом изменения входных данных предполагает выполнение рекурсивного вызова функцией самой себя, когда входные данные на каждом последующем вызове увеличиваются/уменьшаются на некоторую фиксированную величину. В качестве входных данных может выступать как любая одиночная переменная, при каждом последующем вызове увеличивающаяся или уменьшающаяся на какое-то заданное число, так и некоторый массив данных, чей размер с последующими вызовами увеличивается или уменьшается на заданное количество элементов.
Пример рекурсивной декрементной программы со входными данными в виде одиночной переменной. Задача расчёта факториала числа
// определяем функцию/программу для расчёта факториала числа N:
// N! = N x (N-1) x ... x 2 x 1
f(n):
if n == 1 // используем оператор "==", чтобы отличать операцию сравнения от
// операции присваивания "n = 1"
return 1
else
ret = f(n-1)
result = n * ret
return result
main():
factorial_of_five = f(5) // 5! = 5 x 4 x 3 x 2 x 1 = 120
f(n):
if n == 1 // O(1)
return 1 // O(1)
else // O(1)
ret = f(n-1) // ??
result = n * ret // O(1)
return result // O(1)
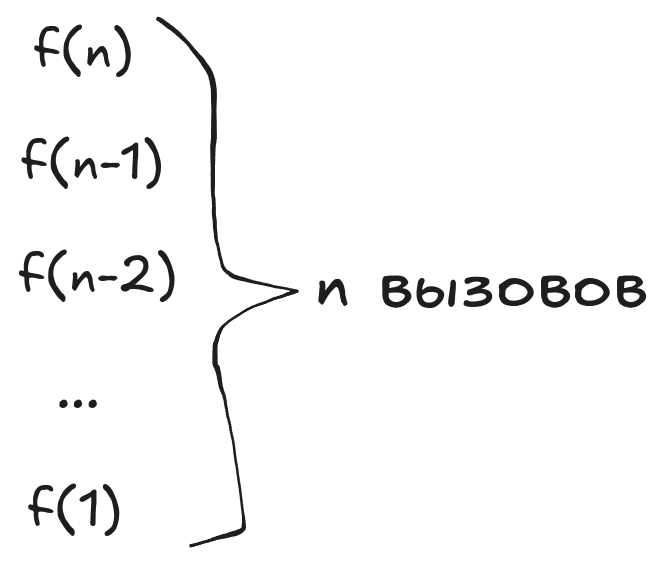
Как посчитать сложность рекурсивных вызовов функции f(...)? Количество вызовов функции равно . Сложность всей программы можно записать в следующем виде:
Наиболее простым случаем вызова является f(1), так как в этом вызове не выполняется никаких вложенных вызовов, а сразу же возвращается значение 1. Очевидно, что вызов f(1) выполняется за константное время . А как быть с остальными вызовами f(k), содержащими в себе вложенные вызовы f(k-1), как рассчитывать сложности их исполнения? Давайте разберёмся с этим неочевидным моментом.
Рассмотрим очень простую рекурсивную программу, не делающую ничего полезного, кроме как передачу и возврат управлений между рекурсивными вызовами:
f(n):
if n == 1
return 1
else
return f(n-1)
main():
res = f(5)
Обратите внимание на то, каким образом в рекурсивных вызовах будут выполняться передачи управлений на уровни ниже и возвраты управлений на уровни выше:
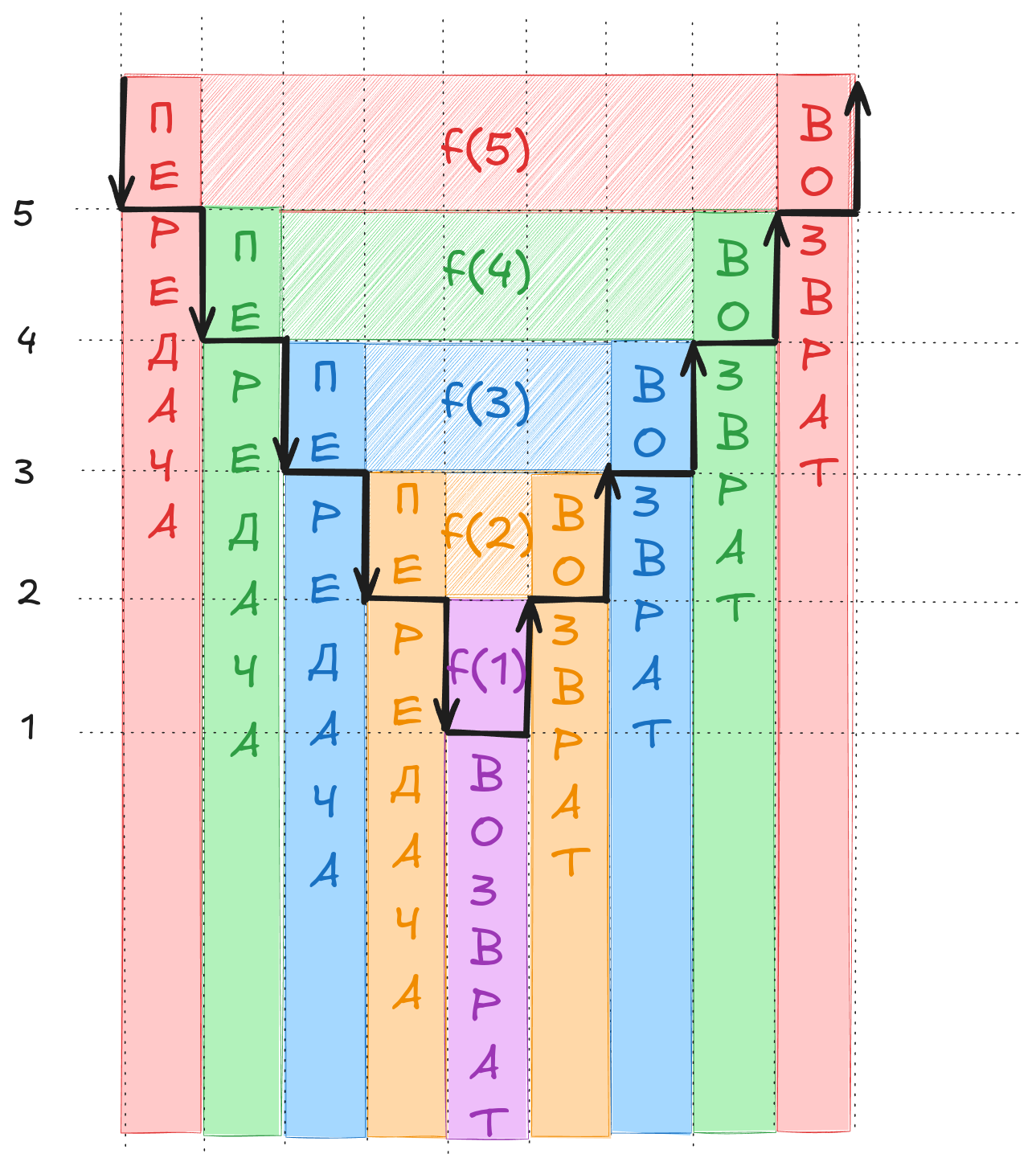
Рассмотрим на представленном изображении время исполнения вызова f(5). На первый взгляд является очевидным, что длительность исполнения вызова f(5) включает в себя следующие отрезки времени:
- передачу управления вызову
f(4); - ожидание завершения исполнения вызова
f(4); - получение возвратного значения из вызова
f(4); - возврат управления в функцию
main(), выполнившую вызовf(5).
Очевидно, что пока не завершится исполнение нижележащего вызова, вышележащий вызов не сможет продолжить своё собственное исполнение, то есть полное время исполнения вышележащих вызовов зависит от времени исполнения всех нижележащих вызовов.
Однако, на этот же самый процесс исполнения рекурсивных вызовов можно посмотреть и под другим углом. Под временем исполнения рекурсивного вызова мы можем и будем понимать только время, непосредственно связанное с полезной работой самого вызова и никак не связанное с полезной работой вложенных (нижележащих) вызовов. Время ожидания на уровне f(5) завершения нижележащего вызова f(4) - это совокупность времён полезной работы для нижележащих вызовов f(4) - f(1). Нет никакого смысла анализировать время ожидания завершения нижележащего вызова f(4) на уровне f(5), когда это время всё равно будет совокупно учтено при рассмотрении процессов работы вызовов f(4) - f(1).
Теперь вернёмся к задаче расчёта факториала. Исходя из сказанного, можем полагать, что процесс работы каждого из вложенного вызовов функции f(k) состоит из следующих шагов:
- Подготовка аргументов рекурсивного вызова
f(k-1). В общем случае время выполнения данного шага может зависеть от размера входных данных задачи. В рассматриваемом примере данный шаг выполняется за константное время, в параметры рекурсивного вызова передаётся аргументk-1. - Делегирование управления вниз, в вызов
f(k-1). Делегирование выполняется за константное время. - Возврат управления из вызова
f(k-1), которому ранее была делегирована задача и который сохранил результаты своей работы в месте, отведённом под возвращаемые данные. Данный шаг также выполняется за константное время. - Чтение возвращённых данных, то есть копирование данных из временного хранилища, созданного вызовом
f(k-1), в пространство текущего вызова. В общем случае время выполнения данного шага может зависеть от размера входных данных задачи. В рассматриваемом примере копированиеret = f(n-1)выполняется за константное время. - Комбинирование результатов вызова
f(k-1)с данными текущего уровня, то есть подготовка конечного результата для возможности его передачи на уровень выше, в вызывающую функцию. В общем случае время выполнения данного шага может зависеть от размера входных данных задачи. В рассматриваемом примере комбинированиеresult = n * retпредставляет собой умножение двух скалярных величин (то есть обычных чисел), а потому его время исполнения не зависит от размера/величины входных данных задачиn(илиk), то есть комбинирование выполняется за константное время. Результат комбинирования сохраняется во временном хранилищеresultфункцииf(k). - Возврат управления в вызывающую функцию, то есть возврат результата комбинирования на уровень выше, в вызов
f(k+1). Возврат управления на уровень выше (возврат функциейf(k)результата), как и делегирование на уровень ниже (выполнение рекурсивного вызова функцииf(k-1)), выполняется за константное время. То есть, если в программе встречается строка кода видаres = call(data), то предполагается, что вызовcallвыполняет требуемые вычисления, результаты вычислений сохраняет во внутреннем временном хранилище, возвращает управление в вызывающую функцию (за константное время), а вызывающая функция, по необходимости, выполняет копирование результатов из временного хранилища в собственное пространство (в хранилищеres). Временное хранилище вызоваf(k-1)после подобных манипуляций высвобождается для возможности дальнейшего переиспользования.
Ещё раз обратите внимание на то, что среди указанных выше шагов отсутствует шаг, связанный с временем ожидания завершения исполнения нижележащего вызова f(k-1), то есть присутствуют только шаги передачи и возврата исполнения, а также комбинирования (вычисления) промежуточных результатов. На уровне исполнения f(k) ожидание завершения вызова f(k-1) является ничем иным как непосредственным процессом исполнения уровня f(k-1). Если в рассчитываемой сложности работы рекурсивной программы явно (в качестве некоторого слагаемого) учитывать некоторый уровень исполнения f(m-1), то этот же уровень f(m-1) не должен учитываться в виде времени ожидания (в виде слагаемого) на уровне f(m), так как оба этих слагаемых по сути означают одно и то же (дублируют друг друга).
Поскольку в формуле расчёта сложности работы всей программы в явном виде уже учитываются сложности всех вызовов , то из всего сказанного выше следует вывод, что при подсчёте сложности работы для данного конкретного уровня вызова f(k) нет необходимости учитывать время, затрачиваемое на ожидание завершения выполнения всех нижележащих (вложенных) вызовов, достаточно только учесть сложности обозначенных в списке выше шагов.
// O(1)
f(n):
if n == 1 // O(1)
return 1 // O(1), строка соответствует только вызову f(1)
else // O(1)
ret = f(n-1) // в рекурсивном вызове учитываются только
// времена передачи и возврата управления
// O(1)
result = n * ret // O(1), комбинирование текущих данных
// и результатов от нижележащего уровня
return result // O(1)
Поскольку любой из вызовов (кроме f(1)) состоит из одних и тех же шагов (подготовки аргументов для рекурсивного вызова, делегирования на уровень ниже через выполнение рекурсивного вызова, получения результата от уровня ниже, комбинирования этого результата с данными текущего уровня, возврата итогового результата на уровень выше), то все вызовы (кроме f(1)) будут выполняться за одно и то же константное время .
В итоге получаем следующий результат:
Пример рекурсивной декрементной программы со входными данными в виде массива чисел. Задача подсчёта суммы элементов в массиве
// Имеется массив array, состоящий из n элементов. Для удобства будем
// считать, что индексация/нумерация элементов в массиве начинается
// с единицы. На каждом последующем рекурсивном вызове размер входных
// данных (размер передаваемого в вызов массива) уменьшается на единицу.
// Также, с целью минимизации операций копирования, будем считать,
// что входные данные в рекурсивные вызовы передаются по ссылкам, а не по
// значениям. Это позволяет избежать трудозатратные операции поэлементного
// копирования требуемых массивов во входные переменные. То есть вызов
// вида f(array[k..m]) означает, что на вход функции f() по ссылке
// передаются элементы исходного массива array в диапазоне индексов
// элементов с k по m. Предполагается, что копирование элементов с k по
// m в функцию f() выполняться не будет, и при этом внутри функции f()
// размер входного массива будет определяться равным не размеру
// исходного массива array, а размеру массива, состоящему из элементов
// с индексами от k до m, то есть size = m - k + 1
f(array):
array_size = size(array)
if array_size == 1:
return array[1]
else:
result = array[1] + f(array[2..array_size])
return result
main():
array[1..n] = [A1, ..., An]
summ = f(array[1..n]) // передача массива по ссылке, операции
// копирования элементов массива внутрь
// функции f() отсутствуют
По аналогии с задачей расчёта факториала числа, каждый из вложенных вызовов f(...) выполняется за константное время и не зависит от , поскольку:
- В длительностях выполнения каждого из вызовов учитываются только времена передачи и возврата управления.
- Отсутствуют накладные временные расходы на формирование входных данных для функции
f(...), то есть отсутствуют операции копирования элементов массива внутрь функцииf(...).
f(array):
array_size = size(array) // O(1)
if array_size == 1: // O(1)
return array[1] // O(1)
else:
result = array[1] + f(array[2..array_size]) // O(1)
return result // O(1)
В итоге получаем следующий результат:
Сложность рекурсивных программ, использующих пропорциональный подход изменения входных данных
Рекурсивная программа с пропорциональным подходом изменения входных данных предполагает выполнение рекурсивного вызова функцией самой себя, где входные данные на каждом последующем вызове пропорционально увеличиваются/уменьшаются (то есть изменяются в некоторое фиксированное число раз). В качестве входных данных может выступать как любая одиночная переменная, при каждом последующем вызове увеличивающаяся или уменьшающаяся в некоторое число раз, так и некоторый массив данных, чей размер с последующими вызовами увеличивается или уменьшается в то же самое число раз.
f(n):
if n <= 1
return 1 // Константное время выполнения строки кода
else
return f(n/2) // Константное время выполнения строки кода.
// В данном примере сразу же возвращаем полученный
// результат на уровень выше (то есть отсутствует
// процесс комбинирования полученного результата с
// какими-либо данными текущего уровня)
Поскольку любая из двух ветвей функций f(...) выполняется за константное время, то для упрощения анализа сложности положим, что обе ветви функции выполняются за одно и то же константное время. Пусть этому константному времени соответствует ровно одна некоторая условная операция.

Примечание
Из курса школьной математики для логарифмов мы знаем следующую формулу:
, где
Из этого следует:
Таким образом, получаем:
Сложность рекурсивных программ, использующих подход “разделяй и властвуй”
Рекурсивные алгоритмы, использующие принцип “разделяй и властвуй” (divide-and-conquer), схожи с алгоритмами, использующими пропорциональный подход сокращения размера входных данных, в том смысле, что принцип "разделяй и властвуй" тоже предполагает выполнение рекурсивного вызова одной и той же функции с пропорционально сокращённым размером входных данных.
Однако, в отличие от рекурсивных программ с простым пропорциональным урезанием размера входных данных, принцип "разделяй и властвуй" не предполагает выполнение простого урезания размера входных данных в некоторое число раз (когда одна из частей входных данных программой просто отбрасывается и внутри программы выполняется один единственный рекурсивный вызов для оставшейся части входных данных), а предполагает:
- Выполнение (по некоторому правилу) разбиения исходных входных данных на составляющие равного размера (то есть выполнение дробления исходной сложной задачи на равные подзадачи, подобные исходной задаче).
- Получение решений (по отдельности, независимо/параллельно) для каждой из подзадач, входящих в исходную задачу. На этом этапе для каждой из подзадач снова вызывается та же самая программа, что была вызвана для исходной задачи.
- Комбинирование (объединение воедино) решений, полученных для подзадач.
В отличие от алгоритмов с обычным пропорциональным уменьшением входных данных, предполагающих наличие внутри программы только одного рекурсивного вызова, алгоритмы, использующие принцип "разделяй и властвуй", содержат внутри рекурсивные вызовы для всех созданных подзадач. Как было сказано ранее, алгоритмы "разделяй и властвуй" не выполняют поэтапного урезания входных данных с отбрасыванием “ненужной” вырезанной части, эти алгоритмы сохраняют все исходные данные, просто эти данные (для упрощения процесса получения решения исходной задачи) делятся на равные части (подзадачи) и решаются по отдельности, а затем комбинируются в одно итоговое решение.
Примечание
Принцип
"разделяй и властвуй"называется именно таким образом, потому что в таком названии несёт подсказку нам:“Если не обладаешь властью над сложной задачей, то раздели эту задачу на подзадачи попроще и властвуй над ними, ведь по отдельности каждой из подзадач проще управлять”.
Поскольку входные данные задачи хоть и подвергаются дроблению на подзадачи, но при этом никуда не отбрасываются, то будет логичным предположить, что, после выполнения комбинирования результатов, полученных при решении подзадач, будет сформирован итоговый результат, соответствующий входным данным исходного размера, причём сложность процесса комбинирования результатов подзадач, в общем случае, может зависеть от размера исходных входных данных. Из этого, в свою очередь, следует, что, в общем случае, сложность вычислений одного рекурсивного вызова f(k) не является константной величиной и зависит от размера данных, подаваемых на вход данного рекурсивного вызова.
Алгоритмы, базирующиеся на принципе разделяй и властвуй, состоят из следующих шагов:
- Подготовка аргументов для рекурсивных вызовов
f(k/m). В общем случае время выполнения данного шага будет зависеть от размера входных данных задачи. Исходные данные размеромkдолжны быть разбиты наmчастей (подзадач), что обычно предполагает выполнение поэлементного копирования входных данных подзадач в свои собственные выделенные переменные, которые будут являться аргументами для рекурсивных вызововf(k/m). Копирование требуемых входных данных подзадачи в переменную-аргумент занимает время . Суммарное время копирования входных данных всех подзадач в переменные-аргументы рекурсивных вызововf(k/m)вычисляется как . - Делегирование процесса расчёта вниз, к следующему вызову
f(k/m). Выполняется за константное время. Количество таких рекурсивных вызовов внутриf(k)зависит от количества подзадач , на которое разбивается исходная задача, поданная на входf(k). - Возврат управлений из вызовов
f(k/m), которым ранее была делегированы подзадачи и которые сохранили результаты своей работы в местах, отведённые под возвращаемые данные. Данный шаг также выполняется за константное время. - Чтение возвращённых данных, то есть копирование данных из временных хранилищ, созданных вызовами
f(k/m), в пространство текущего вызова. Суммарное время чтения результатов всех подзадач (копирования результатов подзадач в пространство текущего вызова) тоже вычисляется как . - Комбинирование полученных результатов подзадач с сохранением результата комбинирования в область памяти, отведённой под возвращаемые функцией
f(k)данные. Сложность процесса комбинирования и сохранения, в общем случае, будет зависеть от размера входных данных , поскольку, после выполнения рекурсивных вызововf(k/m)для созданных подзадач, вызовf(k)должен пройтись для подзадач по сохранённым результатам (по всем элементам всех решённых подзадач) и сформировать результирующие данные размера . - Возврат управления (скомбинированных результатов) на уровень выше, в вызов
f(k*m), который содержит в себеmрекурсивных вызововf(k). Данный шаг выполняется за константное время.
Рекурсивный вызов с константными временами разбиения на подзадачи и комбинирования результатов решения подзадач
Для начала рассмотрим рекурсивные вызовы, в которых времена разбиения на подзадачи и комбинирования результатов решения подзадач не зависят от размера входных данных. Начнём с алгоритма, содержащего два рекурсивных вызова, результаты которых комбинируются путём сложения, выполняемого за константное время:
f(n):
if n <= 1
return 1
else
ret1 = f(n/2) // Задача n делится на две равные
ret2 = f(n/2) // подзадачи n/2. Рекурсивное деление
// всех последующих подзадач пополам
// продолжается до тех пор, пока не будут
// получены элементарные подзадачи n=1
res = ret1 + ret2 // Процесс комбинирования представляет
// собой обычное сложение двух значений,
// полученных для двух рекурсивных вызовов
// f(n/2). Очевидно, что сложность сложения
// двух переменных не зависит от значения n
// и является константной величиной
return res
// Рекурсивный вызов (полезная работа) выполняется за некоторое константное
// время O(1)
f(n):
if n <= 1 // O(1)
return 1 // O(1)
else // O(1)
ret1 = f(n/2) // O(1)
ret2 = f(n/2) // O(1)
res = ret1 + ret2 // O(1)
return res // O(1)
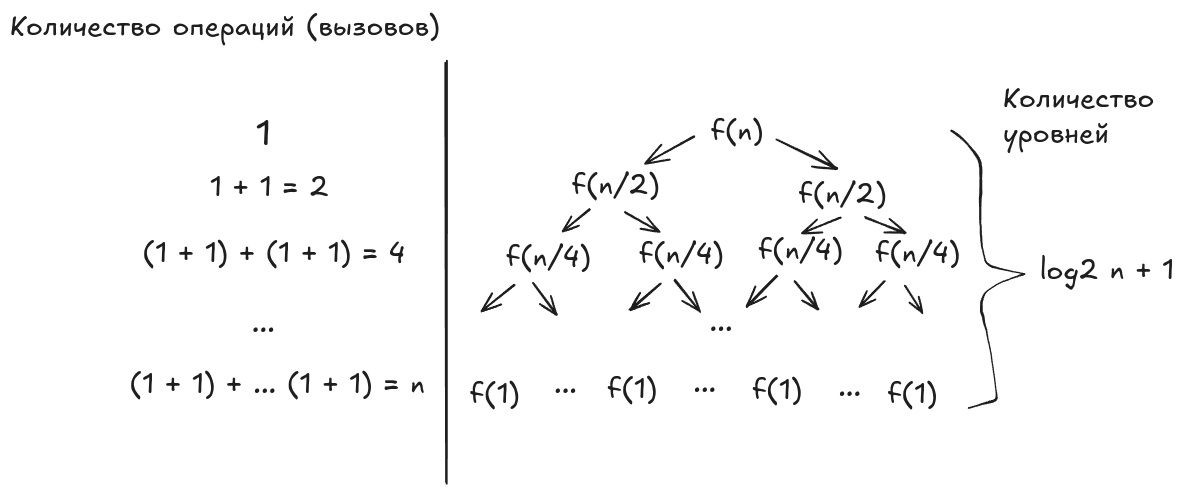
Количество вызовов на каждом последующем уровне (всего уровней) изменяется в соответствии с геометрической прогрессией.
, где
Сумма первых членов геометрической прогрессии высчитывается по следующей формуле:
Тогда, для , получаем:
Немного усложним алгоритм рекурсивного дробления:
f(n):
if n <= 1
return 1
else
return f(n/3) + f(n/3) + f(n/3)
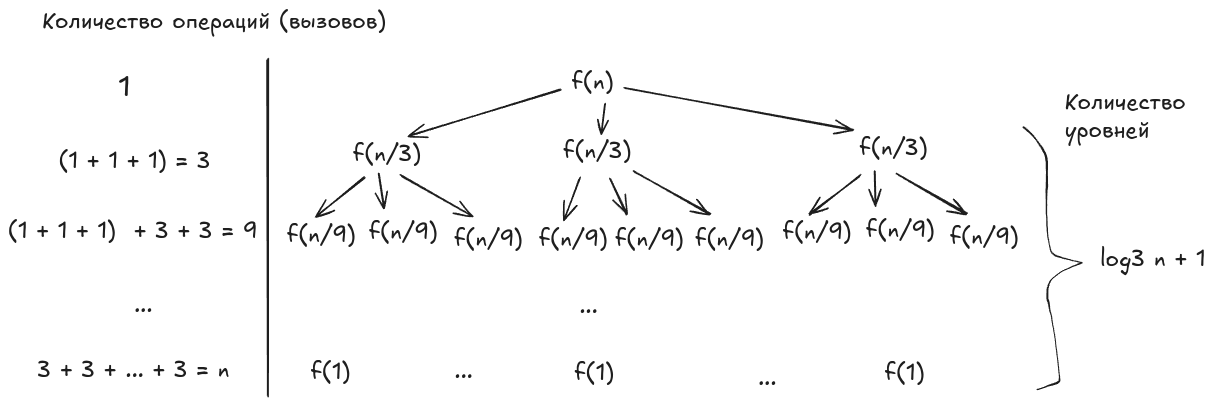
Количество вызовов на каждом последующем уровне (всего уровней) так же, как и в предыдущем случае, изменяется в соответствии с геометрической прогрессией.
, где
Снова воспользуемся формулой для подсчёта суммы первых членов геометрической прогрессии:
Тогда, для , получаем:
Обратите внимание
Cледующий тип рекурсивных программ имеет сложность , причём указанная величина сложности характеризует полное количество рекурсивных вызовов, выполняемых за всё время работы программы, а комбинирование результатов для подзадач в каждом из рекурсивных вызовов при этом выполняется за некоторое константное время:
f(n): if n <= 1 return 1 else return f(n/k) + f(n/k) + ... + f(n/k) // k слагаемых
Обобщение формулы расчёта сложности программ, содержащих рекурсивные вызовы с константными временами разбиения на подзадачи и комбинирования результатов решения подзадач
Мы знаем, что время выполнения представленного ниже варианта программы линейно зависит от размера входных данных :
f(n):
if n <= 1
return 1
else
return f(n/2) + f(n/2)
Теперь рассмотрим, как изменится временная сложность после внесения в данную программу небольшого изменения:
f(n):
if n <= 1
return 1
else
return f(n/2) + f(n/2) + f(n/2) // обратите внимание на то, что теперь
// выполняется не тройной вызов f(n/3),
// как было рассмотрено для линейного
// случая выше, а тройной вызов f(n/2)
Количество уровней вложенных вызовов, начиная с самого первого (внешнего) вызова, будет равно . Количество вызовов на каждом последующем уровне будет в 3 раза больше, чем не предыдущем уровне. Из этого следует, что мы рассматриваем следующую геометрическую прогрессию (каждый элемент которой отображает количество вызовов очередного уровня):
, где
В данном случае , откуда получаем:
Примечание
Из курса школьной математики для логарифмов мы знаем следующую формулу:
Из этого следует:
Таким образом, получаем:
Важный вывод
В конечном итоге, аналогичным образом, мы можем найти оценку временной сложности для обобщённой версии рассмотренной программы:
f(n): if n <= 1 return 1 else return f(n/k) + ... + f(n/k) // m вызовов
Поскольку обобщение было получено из формулы для геометрической прогрессии с , то из этого следует, что в обобщённой формуле должно выполняться условие . Также очевидно, что в формуле должно выполняться условие , так как в противном случае все вложенные вызовы
f(n/k)превратятся в бесконечно зацикленные вызовыf(n).
При помощи обобщённой формулы можно вывести следующие ранее рассмотренные случаи:
f(n):
if n <= 1
return 1
else
return f(n/2) + f(n/2) // k = 2, m = 2
f(n):
if n <= 1
return 1
else
return f(n/3) + f(n/3) + f(n/3) // k = 3, m = 3
Рекурсивный вызов с временами разбиения на подзадачи и комбинирования результатов решения подзадач, зависящими от размера входных данных
Еще раз обратим внимание на то, что в алгоритмах "разделяй и властвуй" количество рекурсивных вызовов на каждом последующем уровне рекурсии изменяется в соответствии с геометрической прогрессией: . Количество уровней рекурсии при этом логорифмическим образом зависит от размера входных данных (для рассматриваемого примера эта зависимость равна ).
Суммарное количество вызвов по всем уровням рекурсии линейно зависит от размера входных данных: . Интуитивно линейный характер результата можно объяснить тем, что хотя количество выполняемых рекурсивных вызовов растёт быстрым нелинейным образом от уровня к уровню, тем не менее эта быстрая нелинейная скорость роста сглаживается/тормозится/нивилируется медленной нелинейной скоростью роста самого числа рекурсивных уровней по мере увеличения размера входных данных. Благодаря этому характер итоговой куммулятивной (скомбинированной) зависимости как бы усредняется до линейного вида.
В рассмотренном примере сложность алгоритма оценивалась по количеству выполняемых вызовов, сложность каждого отдельного вызова при этом не учитывалась, так как каждый из вызовов выполняется за некоторое константное время и не зависит от размера входных данных (мы полагаем, что каждый из вызовов выполняется за одну условную операцию).
// Рекурсивный вызов (полезная работа) выполняется за некоторое константное
// время O(1)
f(n):
if n <= 1
return 1 // O(1)
else
return f(n/2) + f(n/2) // O(1) - время комбинирования (в данном
// случае суммирования) результатов
// константно
Такой подход к расчёту оценки сложности работы алгоритма будет работать только в случаях, когда времена формирования подзадач и комбинирования результатов являются постоянными. Однако, очень часто указанные времена зависят от размера входных данных. Например, при работе с массивом данных, процесс разбиения исходной задачи на подзадачи может представлять собой создание нескольких подмассивов, каждый из которых должен формироваться путём поочерёдного копирования части элементов из исходного массива. После решения подзадач может быть необходимо сохранить в новых переменных возвращённые подмассивы-решения, затем может потребоваться сформировать итоговый массив-решение путём переупорядочивания элементов из сохранённых подмассивов-решений. Таким образом, очень часто складывается ситуация, когда сложности рекурсивных вызовов нельзя считать равными , то есть в оценке сложности работы алгоритма приходится учитывать сложность выполнения каждого из рекурсивных вызовов, а характер итоговой зависимости (временной сложности работы алгоритма) не является линейным. Классическим примером подобного алгоритма является алгоритм сортировки слиянием (merge sort), рассматриваемый далее.
ВПЕРЁД ⇒
⇐ НАЗАД
Источники
Категория
Теги
- Алгоритм Алгоритм
- Цикл Цикл
- Время-работы Время-работы
- Сложность-по-времени Сложность-по-времени
- Временная-сложность Временная-сложность
- Time-complexity Time-complexity
- Сложность-вычислений Сложность-вычислений
- Big-O Big-O
- Рекурсия Рекурсия
- Логарифм Логарифм
- Геометрическая-прогрессия Геометрическая-прогрессия