ВПЕРЁД ⇒
⇐ НАЗАД
Сортировка слиянием (merge sort)
Идея работы алгоритма
Имеется массив, который необходимо отсортировать.
Принцип работы:
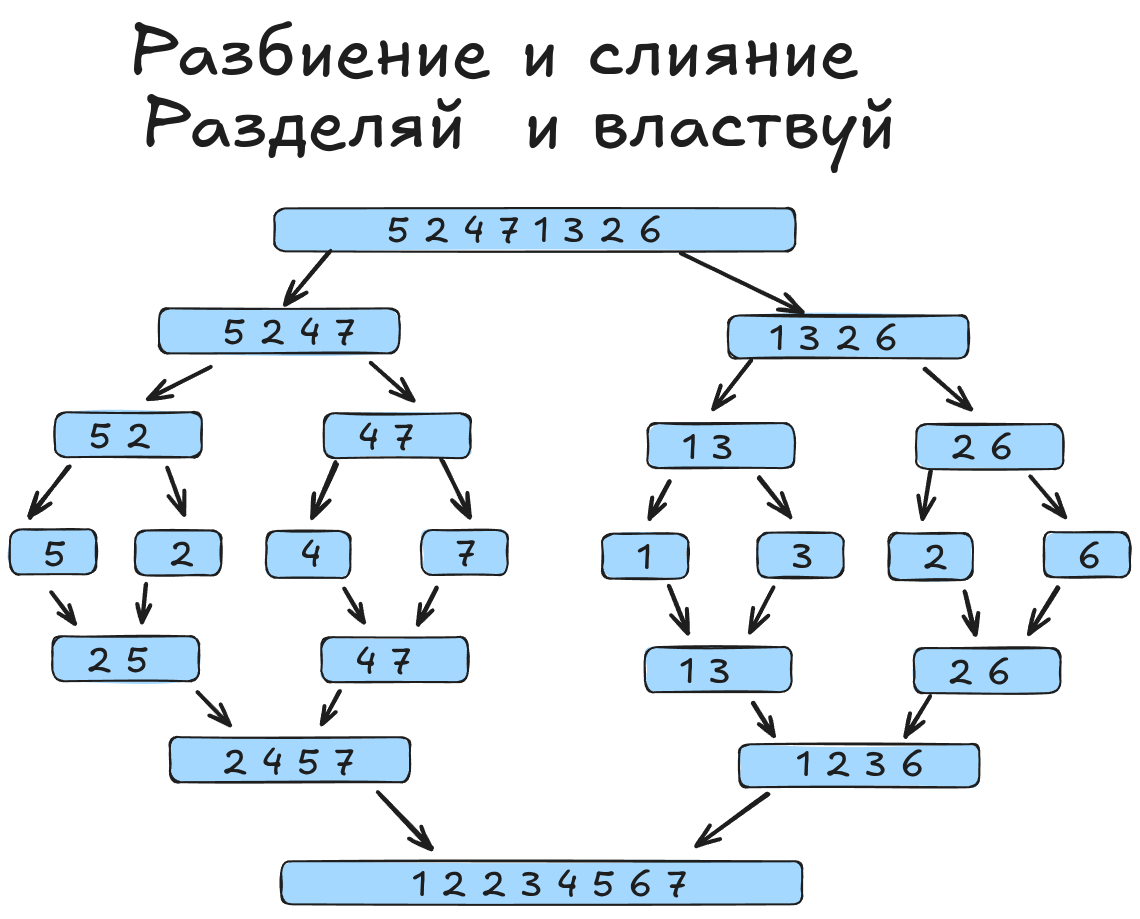
- Декомпозируем (разбиваем) исходный массив на два подмассива и рекурсивно применяем этот же алгоритм сортировки в отдельности к каждому из подмассивов. Принцип разделения исходной задачи на подзадачи и решения каждой из задач по отдельности носит название принципа
"разделяй и властвуй". - Выполняем слияние двух отсортированных подмасcивов.
Сортировка слиянием на английском языке носит название merge sort.
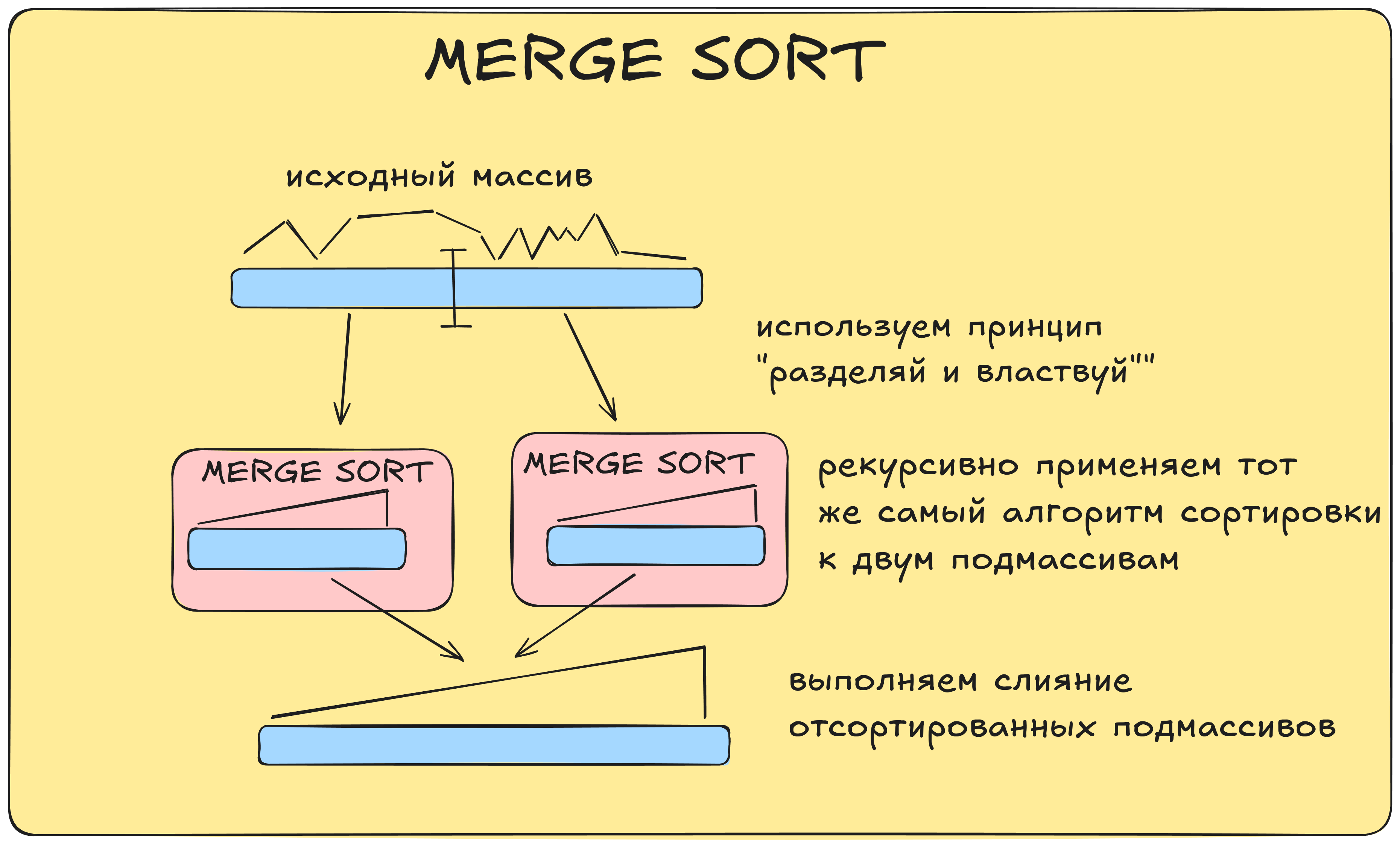
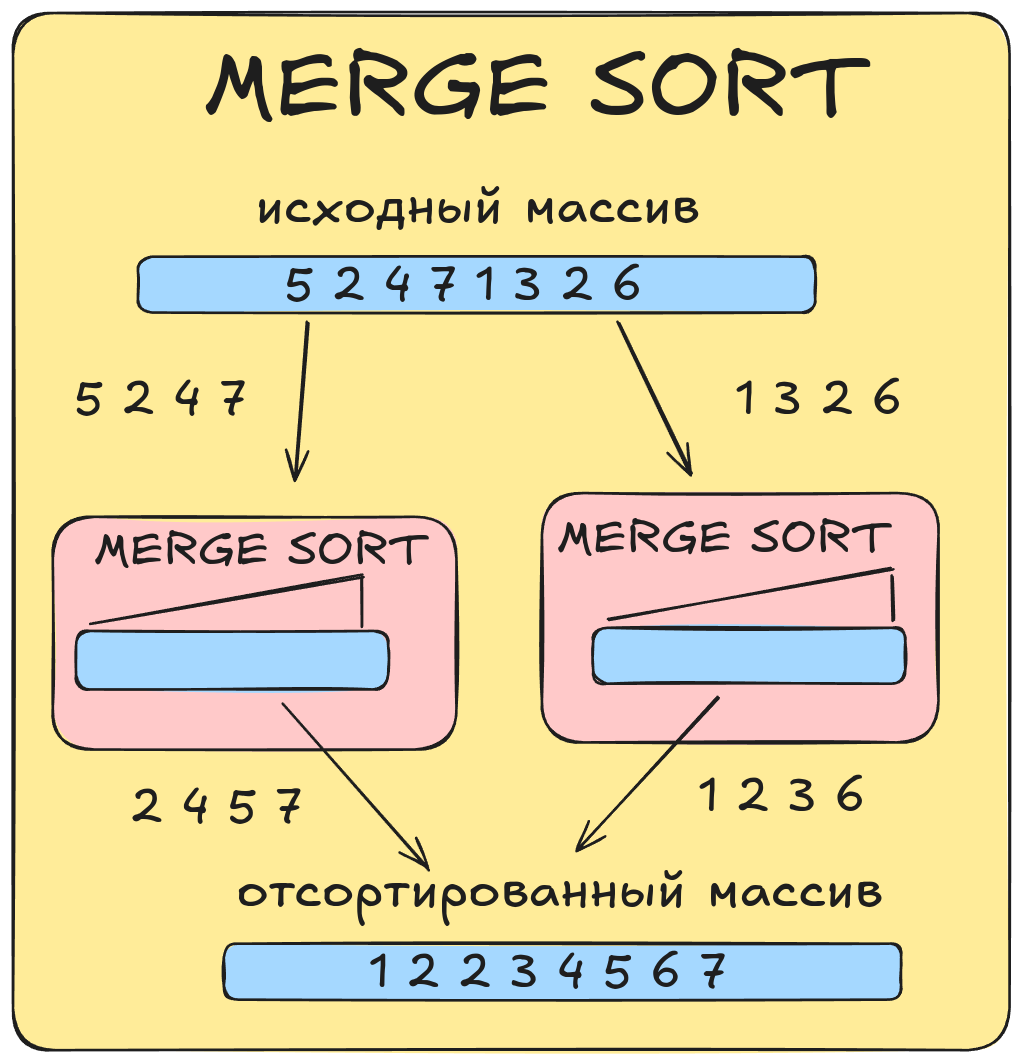
Рекурсивное применение алгоритма сортировки к подмассивам (а конкретно, разбиение одних подмассивов на другие подмассивы) выполняется до тех пор, пока получаемые подмассивы не станут состоять из одного элемента.
Алгоритм слияния отсортированных подмассивов (комбинирования результатов для созданных подзадач сортировки)
Сложность и реализация алгоритма слияния отсортированных подмассивов
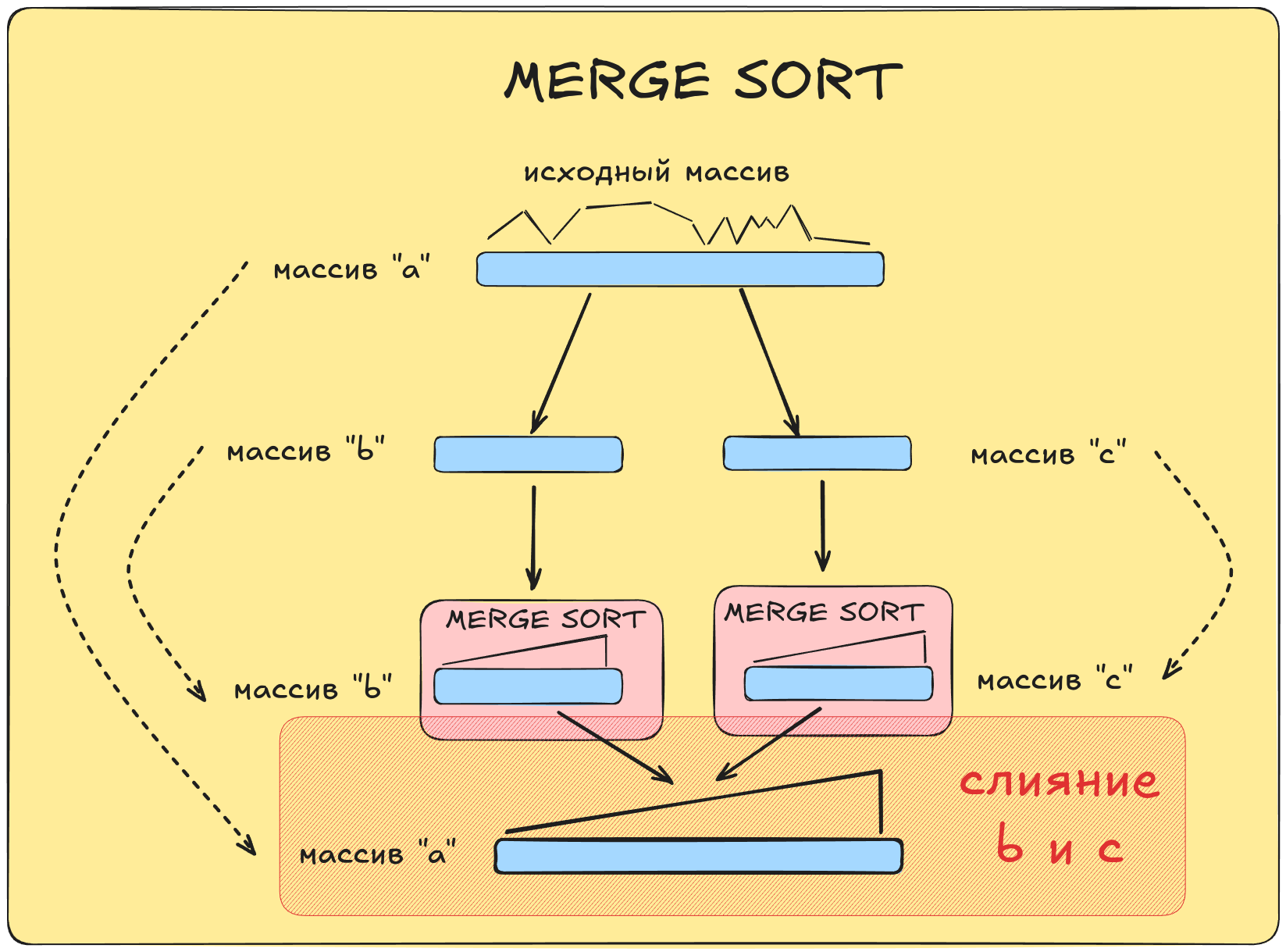
Предположим, что исходный массив a разбит на два подмассива b и c, и каждый из подмассивов отсортирован в требуемом порядке расположения элементов. Необходимо правильно перенести элементы из отсортированных подмассивов b и c в исходный массив a.
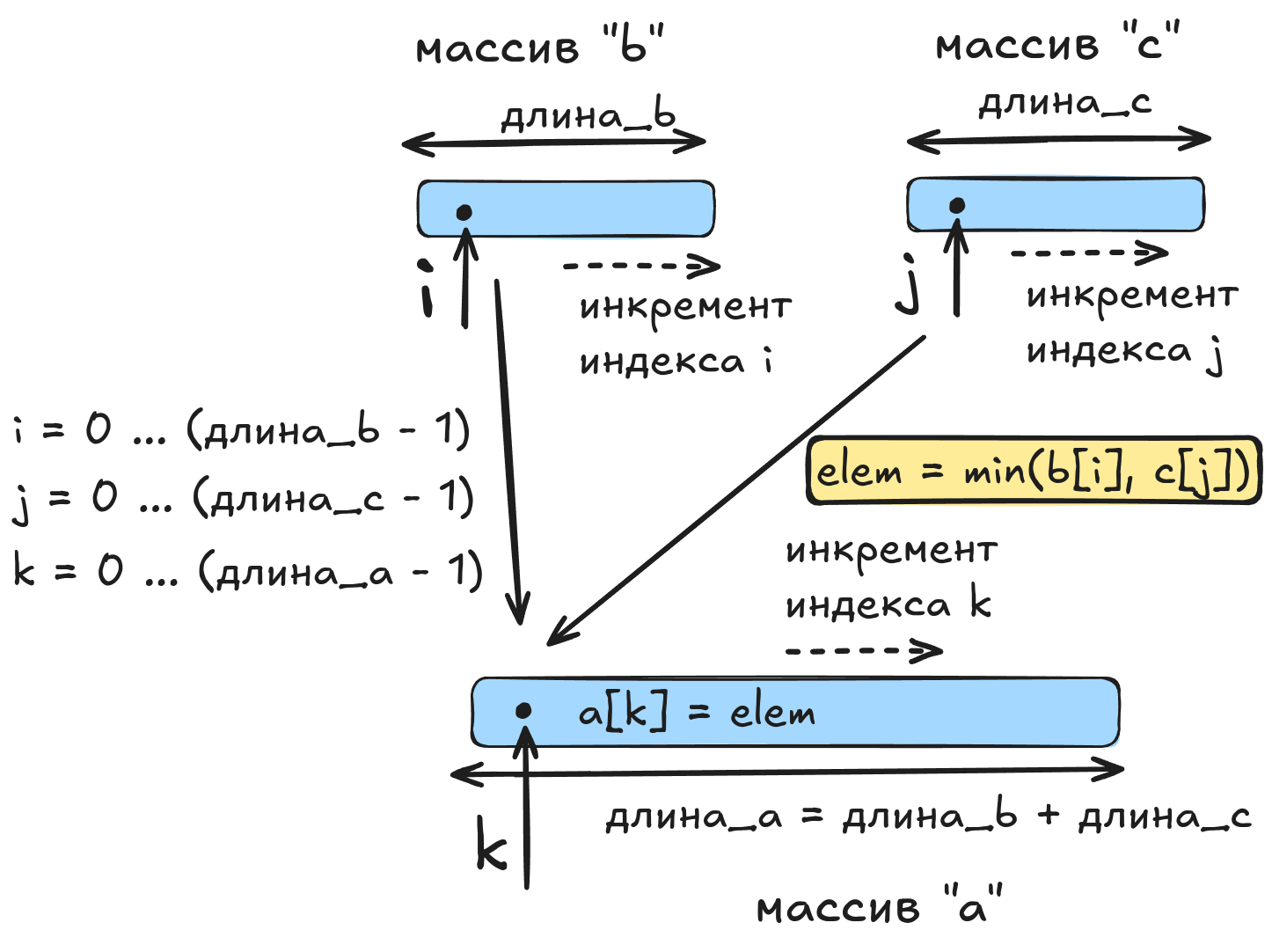
Если провести аналогию, то процесс слияния двух подмассивов представляет собой циклическое сравнение верхних “патронов” (элементов) из двух “магазинов” b и c, когда наиболее подходящий “патрон” (в нашем случае минимальный из двух сравниваемых элементов) извлекается из нужного “магазина” и вставляется в “магазин” a. Элементы в каждом из “магазинов” b и c уже расположены в порядке возрастания, благодаря чему среди верхних элементов “магазинов” всегда присутствует элемент, являющийся наименьшим среди всех элементов “магазинов” b и c. Указанный наименьший элемент (для двух “магазинов” b и c) помещается в “магазин” a, после чего среди обновлённых верхних элементов “магазинов” b и c снова можно найти элемент, являющийся наименьшим среди оставшихся элементов в b и c. Итеративно извлекая подобный минимальный элемент из b (или c), и помещая его в a, будем постепенно заполнять “магазин” a элементами в порядке их возрастания. Очевидно, что если в двух “магазинах” b и c суммарно находится “патронов”, то число вставок “патронов” в “магазин” a также будет равно . Таким образом, временная сложность алгоритма слияния двух отсортированных подмассивов будет линейным образом зависеть от длины массива :
Псевдокод алгоритма слияния двух отсортированных подмассивов выглядит следующим образом:
merge(b, c):
a = [0, 0, ..., 0] // инициализация массива результатов,
// который будет возвращён функцией merge()
// size(a) = size(b) + size(c)
i = 0, j = 0, k = 0
while i < size(b) or j < size(c): // будет size(b) + size(c) == size(a)
// итераций
if j == size(c) or (i < size(b) and b[i] < c[j]):
a[k] = b[i]
i = i + 1
else:
a[k] = c[j]
j = j + 1
k = k + 1
return a
Корректность алгоритма слияния отсортированных подмассивов
Доказательство корректности работы алгоритма:
Инициализация. Перед стартом алгоритма слияния размер целевого отсортированного массива равен 0. Это значит, что в массиве не могут содержаться никакие элементы, чей порядок расположения хоть как-то нарушал бы инвариант цикла, заключающийся в том, что все элементы массива должны быть расположены в требуемом порядке возрастания.Сохранение. Указанный выше “магазинный” подход извлечения элементов из подмассивов гарантирует, что в целевой массив элементы из подмассивов всегда будут попадать в порядке их возрастания. То есть на всех итерациях цикла заполнения целевого массива элементами подмассивов инвариант цикла (отсортированность элементов в целевом массиве) всегда будет сохраняться.Завершение. Также “магазинный” подход (итеративное извлечение наименьшего элемента среди оставшихся элементов подмассивов) гарантирует, что рано или поздно в целевом массиве окажутся все элементы из подмассивов, то есть “магазинный” подход гарантирует, что алгоритм слияния рано или поздно завершится.
Сортировка массива через рекурсию
Сложность и реализация алгоритма сортировки
Алгоритм сортировки исходного массива:
- Если размер входного массива равен единице, то в качестве результата сортировки возвращаем единственный элемент этого массива (возращаем массив ). В противном случае переходим к следующему шагу.
- Делим пополам входной массив (создаём подмассивы и ). Если размер входного массива - чётное число, то два подмассива будут иметь одинаковый размер. Если размер входного массива - нечётное число, то размер одного из подмассивов будет на единицу больше размера другого подмассива.
- Для каждого из созданных подмассивов и снова вызываем этот же самый алгоритм сортировки.
- Отсортированные подмассивы и обратно объединяем в массив (описание merge-этапа см. выше).
- Возвращаем отсортированный массив .
Псевдокод алгоритма сортировки массива выглядит следующим образом:
// Вся сортировка занимает T(n) инструкций
sort(a):
m = size(a) // k1 инструкций (предполагаем, что размер
// массива можно определить за константное время,
// например, если нам известны первый и последний
// индексы массива)
// k1 = 0 (строка кода выполняется за константное
// время)
if m == 1: // k2 инструкций (k2 = 0, так как строка кода
// выполняется за константное время)
return a // k3 инструкций (k3 = 0, так как строка кода
// выполняется за константное время)
// в целочисленном делении m/2 остаток отбрасывается
b = a[0..m/2-1] // k4*m/2 инструкций (один элемент копируется
// из массива a в массив b за k4 инструкций,
// m/2 элементов копируются за k4*m/2 инструкций).
// Занулять k4 здесь нельзя, так как нужно помнить,
// что копирование всех требуемых элементов из a
// в b зависит от размера входных данных m.
//
// Сложность вычислений строки кода: O(m/2)
c = a[m/2..m-1] // k5*m/2 инструкций, если m - чётное число,
// или k5*(m/2 + 1) инструкций,
// если m - нечётное число.
//
// Сложность вычислений строки кода: O(m/2)
b = sort(b) // Сложность вычислений внутри sort(b) полагаем
// равной O(1), так как в процедуре
// выполнения рекурсивного вызова
// должны учитываться только константные времена
// передачи и возврата управления, но не само время
// исполнения вызова, которое будет учтено отдельным
// слагаемым при подсчёте суммарного времени работы
// алгоритма. Однако, кроме самих вычислений внутри
// sort(b), также необходимо учесть процедуру
// копирования элементов из b во внутренний входной
// параметр (переменную) вызова sort(b),
// а также процедуру копирования результатов
// работы sort(b) обратно в b. Таким образом,
// суммарная сложность строки кода равна:
// O(m/2) + O(1) + O(m/2) = O(m)
c = sort(c) // Сложность вычислений строки кода равна O(m)
a = merge(b, c) // Сложность процедуры слияния merge() равна O(m),
// сложность копирования b во входной параметр
// вызова merge() равна O(m/2), сложность копирования
// массива с во входной параметр вызова merge()
// равна O(m/2), сложность копирования результатов
// вызова merge() в массив a равна O(m). Итоговая
// сложность строки кода:
// O(m/2) + O(m/2) + O(m) + O(m) = O(m)
return a // k7*m инструкций (предполагаем, что массив a может
// поэлементно копироваться в некоторый выходной
// буфер функции)
//
// Сложность вычислений строки кода: O(m)
Сложность выполнения одного рекурсивного вызова:
Для упрощения процесса анализа сложности работы всего алгоритма сначала рассмотрим, как выглядят рекурсивные вызовы алгоритма на разных уровнях рекурсии. Иерархия рекурсивных вызовов идентична иерархии рекурсивных вызовов с константными временами разбиения на подзадачи и комбинирования результатов решения подзадач.
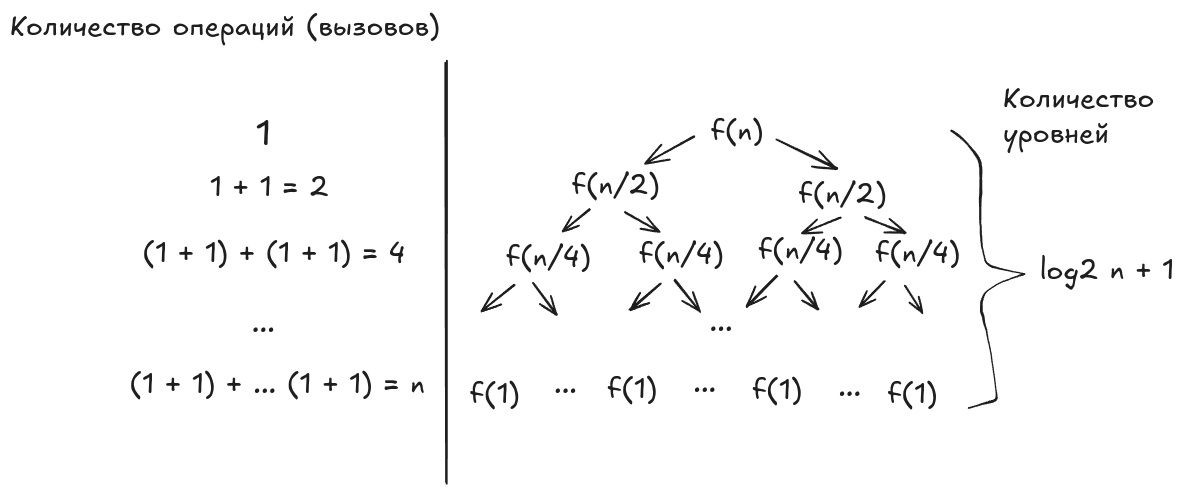
На каждом последующем уровне размер входных данных, подаваемых в каждый рекурсивный вызов одного и того же уровня, уменьшается вдвое в сравнении с предыдущим уровнем. Так будет продолжаться до тех пор, пока на самом нижнем уровне на вход рекурсивных вызовов не станут подаваться одиночные элементы, количество рекурсивных вызовов при этом станет равно размеру входных данных исходной задачи. Таким образом, на каждом последующем уровне количество вызовов увеличивается вдвое, а размер входных данных вызовов, наоборот, уменьшается вдвое. Учитывая оценку сложности выполнения одного рекурсивного вызова , получаем, что суммарная сложность вычислений вызовов, расположенных на одном уровне рекурсии, равна .
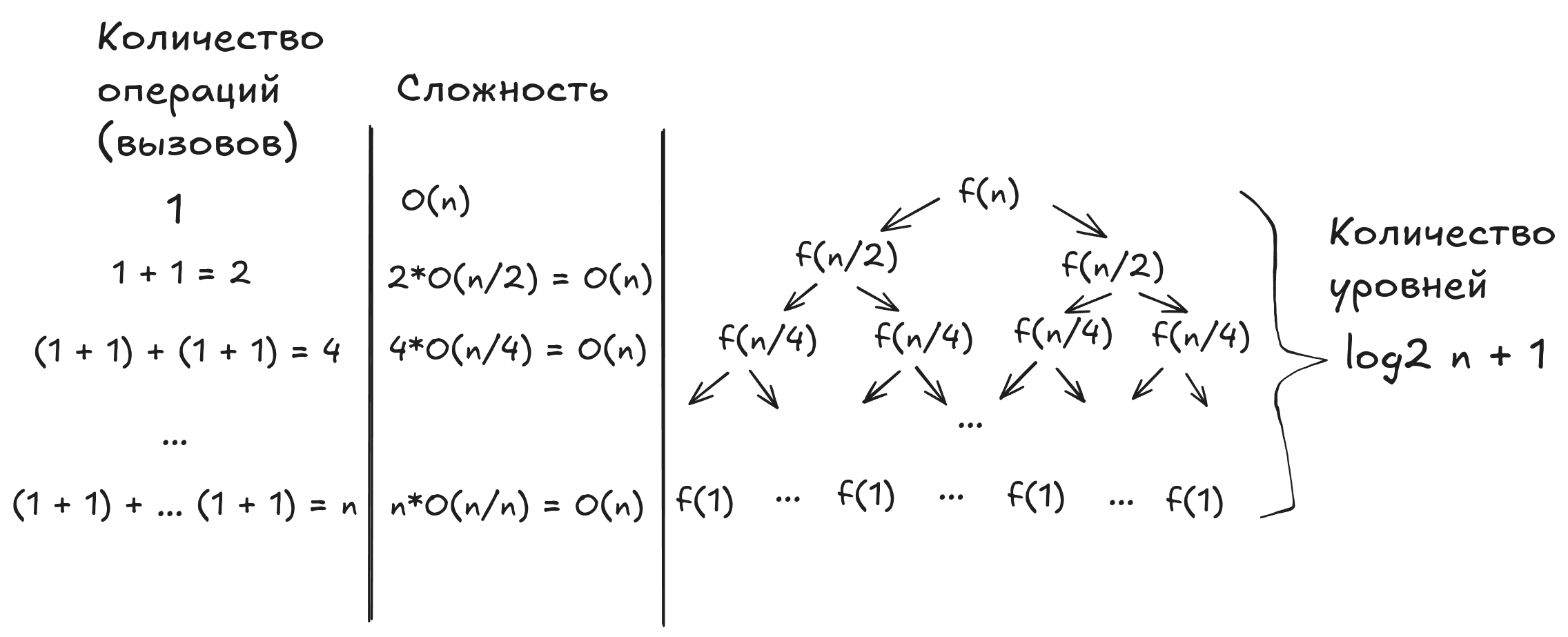
Поскольку мы знаем, что алгоритм состоит из уровней рекурсии, то мы можем вычислить итоговую оценку сложности выполнения алгоритма сортировки слиянием:
ВПЕРЁД ⇒
⇐ НАЗАД
Источники
Категория
Теги
- Алгоритм Алгоритм
- Цикл Цикл
- Время-работы Время-работы
- Сложность-по-времени Сложность-по-времени
- Временная-сложность Временная-сложность
- Time-complexity Time-complexity
- Сложность-вычислений Сложность-вычислений
- Big-O Big-O
- Рекурсия Рекурсия
- Логарифм Логарифм
- Геометрическая-прогрессия Геометрическая-прогрессия